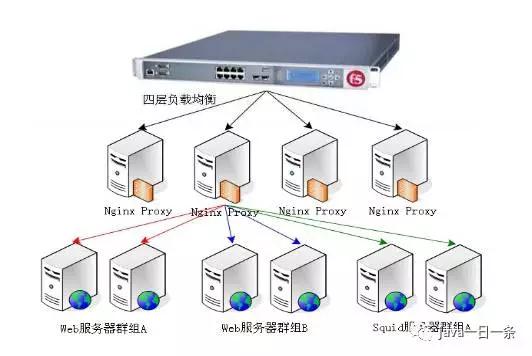
多种负载均衡算法及其 Java 代码实现
来源:原创 时间:2017-11-15 浏览:0 次首先给我们介绍下什么是负载均衡
负载均衡 树立在现有网络结构之上,它供给了一种廉价有用通明的办法扩展 网络设备和 效劳器的带宽、添加 吞吐量、加强网络数据处理才能、进步网络的灵敏性和可用性。
负载均衡,英文名称为Load Balance,其意思就是分摊到多个操作单元上进行履行,例如Web 效劳器、 FTP效劳器、 企业要害应用效劳器和其它要害使命效劳器等,然后共同完成工作使命。
多种负载均衡算法及其Java代码完成
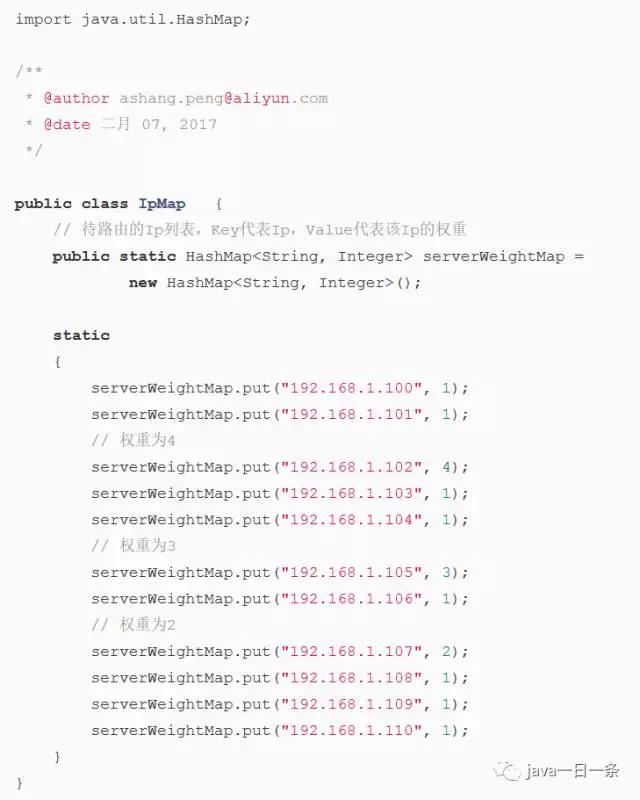
本文叙述的是”将外部发送来的恳求均匀分配到对称结构中的某一台效劳器上”的各种算法,并以Java代码演示每种算法的具体完成,OK,下面进入正题,在进入正题前,先写一个类来模仿Ip列表:
轮询(Round Robin)法
轮询调度算法的原理是每一次把来自用户的恳求轮番分配给内部中的效劳器,从1开端,直到N(内部效劳器个数),然后从头开端循环。算法的长处是其简洁性,它无需记载当时一切衔接的状况,所以它是一种无状况调度。
其代码完成大致如下:
因为serverWeightMap中的地址列表是动态的,随时可能有机器上线、下线或许宕机,因而为了防止可能呈现的并发问题,办法内部要新建局部变量serverMap,现将serverMap中的内容仿制到线程本地,以防止被多个线程修正。这样可能会引进新的问题,仿制今后serverWeightMap的修正无法反映给serverMap,也就是说这一轮挑选效劳器的过程中,新增效劳器或许下线效劳器,负载均衡算法将无法获悉。新增无所谓,如果有效劳器下线或许宕机,那么可能会拜访到不存在的地址。因而,效劳调用端需求有相应的容错处理,比方从头建议一次server挑选并调用。
关于当时轮询的方位变量pos,为了确保效劳器挑选的次序性,需求在操作时对其加锁,使得同一时间只能有一个线程能够修正pos的值,不然当pos变量被并发修正,则无法确保效劳器挑选的次序性,甚至有可能导致keyList数组越界。
轮询法的长处在于:企图做到恳求搬运的肯定均衡。
轮询法的缺陷在于:为了做到恳求搬运的肯定均衡,有必要支付适当大的价值,因为为了确保pos变量修正的互斥性,需求引进重量级的失望锁synchronized,这将会导致该段轮询代码的并发吞吐量发作显着的下降。
随机(Random)法
经过体系的随机算法,依据后端效劳器的列表巨细值来随机选取其间的一台效劳器进行拜访。由概率核算理论能够得知,跟着客户端调用效劳端的次数增多,
其实际作用越来越接近于平均分配调用量到后端的每一台效劳器,也就是轮询的成果。
随机法的代码完成大致如下:
全体代码思路和轮询法共同,先重建serverMap,再获取到server列表。在选取server的时分,经过Random的nextInt办法取0~keyList.size()区间的一个随机值,然后从效劳器列表中随机获取到一台效劳器地址进行回来。依据概率核算的理论,吞吐量越大,随机算法的作用越接近于轮询算法的作用。
源地址哈希(Hash)法
源地址哈希的思维是依据获取客户端的IP地址,经过哈希函数核算得到的一个数值,用该数值对效劳器列表的巨细进行取模运算,得到的成果就是客服端要拜访效劳器的序号。选用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端效劳器列表不变时,它每次都会映射到同一台后端效劳器进行拜访。
源地址哈希算法的代码完成大致如下:
前两部分和轮询法、随机法一样就不说了,不同在于路由挑选部分。经过客户端的ip也就是remoteIp,取得它的Hash值,对效劳器列表的巨细取模,成果就是选用的效劳器在效劳器列表中的索引值。
源地址哈希法的长处在于:确保了相同客户端IP地址将会被哈希到同一台后端效劳器,直到后端效劳器列表改变。依据此特性能够在效劳消费者与效劳供给者之间树立有状况的session会话。
源地址哈希算法的缺陷在于:除非集群中效劳器的十分安稳,根本不会上下线,不然一旦有效劳器上线、下线,那么经过源地址哈希算法路由到的效劳器是效劳器上线、下线前路由到的效劳器的概率十分低,如果是session则取不到session,如果是缓存则可能引发”雪崩”。如果这么解说不适合了解,能够看我之前的一篇文章MemCache超具体解读,共同性Hash算法部分。
加权轮询(Weight Round Robin)法
不同的后端效劳器可能机器的装备和当时体系的负载并不相同,因而它们的抗压才能也不相同。给装备高、负载低的机器装备更高的权重,让其处理更多的请;而装备低、负载高的机器,给其分配较低的权重,下降其体系负载,加权轮询能很好地处理这一问题,并将恳求次序且依照权重分配到后端。加权轮询法的代码完成大致如下:
与轮询法相似,只是在获取效劳器地址之前添加了一段权重核算的代码,依据权重的巨细,将地址重复地添加到效劳器地址列表中,权重越大,该效劳器每轮所取得的恳求数量越多。
加权随机(Weight Random)法
与加权轮询法一样,加权随机法也依据后端机器的装备,体系的负载分配不同的权重。不同的是,它是依照权重随机恳求后端效劳器,而非次序。
这段代码适当所以随机法和加权轮询法的结合,比较好了解,就不解说了。
最小衔接数(Least Connections)法
最小衔接数算法比较灵敏和智能,因为后端效劳器的装备不尽相同,关于恳求的处理有快有慢,它是依据后端效劳器当时的衔接状况,动态地选取其间当时
积压衔接数最少的一台效劳器来处理当时的恳求,尽可能地进步后端效劳的使用功率,将担任合理地分流到每一台效劳器。
前面几种办法费尽心思来完成效劳消费者恳求次数分配的均衡,当然这么做是没错的,能够为后端的多台效劳器平均分配工作量,最大程度地进步效劳器的使用率,可是实际状况是否真的如此?实际状况中,恳求次数的均衡真的能代表负载的均衡吗?这是一个值得考虑的问题。
上面的问题,再换一个视点来说就是:今后端效劳器的视角来调查体系的负载,而非恳求建议方来调查。最小衔接数法便归于此类。
最小衔接数算法比较灵敏和智能,因为后端效劳器的装备不尽相同,关于恳求的处理有快有慢,它正是依据后端效劳器当时的衔接状况,动态地选取其间当时积压衔接数最少的一台效劳器来处理当时恳求,尽可能地进步后端效劳器的使用功率,将负载合理地分流到每一台机器。因为最小衔接数规划效劳器衔接数的汇总和感知,规划与完成较为繁琐,此处就不说它的完成了。